Databricks Connector
The Databricks component allows you to list, import, and automate Databricks jobs.
Prerequisites
- Version 9.2.9 or later
- Component Connection Management version 1.0.0.3
- Privileges Required to use Connections
- Privileges Required to use Databricks
Contents of the Component
| Object Type | Name | Description |
|---|---|---|
| Application | GLOBAL.Redwood.REDWOOD.Databricks | Integration connector with the Databricks system |
| ConstraintDefinition | REDWOOD.Redwood_DatabricksConnectionConstraint | Constraint for Databricks Connection fields |
| ExtensionPoint | REDWOOD.Redwood_DatabricksConnection | Databricks Connector |
| Process Definition | REDWOOD.Redwood_Databricks_ImportJob | Import a job from Databricks |
| Process Definition | REDWOOD.Redwood_Databricks_RunJob | Run a job in Databricks |
| Process Definition | REDWOOD.Redwood_Databricks_RunJob_Template | Template definition to run a job in Databricks |
| Process Definition | REDWOOD.Redwood_Databricks_ShowJobs | List all existing jobs in Databricks |
| Process Definition Type | REDWOOD.Redwood_Databricks | Databricks Connector |
| Library | REDWOOD.Redwood_Databricks | Library for Databricks connector |
Process Definitions
Redwood_Databricks_ImportJob
Import a job from Databricks. Imports one or more Databricks jobs as RunMyJobs Process Definitions. Specify a Name Filter to control what processes are imported, and Generation Settings to control the attributes of the imported definitions.
Parameters
| Tab | Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|---|
| Parameters | connection | Connection | The Connection object that defines the connection to the Databricks application. | String | In | ||
| Parameters | filter | Job Name Filter | This filter can be used to limit the amount of jobs returned to those which name matches the filter. Wildcards * and ? are allowed. | String | In | ||
| Parameters | overwrite | Overwrite Existing Definition | When set to Yes, if a definition already exists with the same name as the name generated for the imported object, it will be overwritten with the new import. When set to No, the import for that template will be skipped if a definition with the same name already exists. | String | In | N | Y,N |
| Generation Settings | targetPartition | Partition | The Partition to create the new definitions in. | String | In | ||
| Generation Settings | targetApplication | Application | The Application to create the new definitions in. | String | In | ||
| Generation Settings | targetQueue | Default Queue | The default Queue to assign to the generated definitions. | String | In | ||
| Generation Settings | targetPrefix | Definition Name Prefix | The prefix to add onto the name of the imported Databricks Job to create the definition name. | String | In | CUS_DBCKS_ |
Redwood_Databricks_RunJob
Runs a Databricks job and monitors it until completion. The RunMyJobs Process will remain in a Running state until the Databricks job completes. If the Databricks Job succeeds, the RunMyJobs process will complete successfully. If the Databricks Job fails, the RunMyJobs process will complete in Error, and any available error information is written to the stdout.log file. Parameters are available on the definition to pass input parameters for the different types of Databricks tasks. For example, adding a value to the Python Parameters parameter will make that parameter available to all Python tasks in the Databricks Job. If the job does not require parameters for a certain task type, leave that parameter empty. See the parameters table below for more information.
Parameters
| Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|
| connection | Connection | The Connection object that defines the connection to the Databricks application. | String | In | ||
| jobId | Job Id to run | This is the Job Id in Databricks to execute | String | In | ||
| sparkJarParameters | Spark Jar Parameters | An array of Spark Jar Parameters to be used on the Databricks Job | String | In | ||
| sparkSubmitParameters | Spark Submit Parameters | An array of Spark Submit Parameters to be used on the Databricks Job | String | In | ||
| notebookParameters | Notebook Parameters | An array key=value pairs of Notebook Parameters to be used on the Databricks Job | String | In | ||
| pythonParameters | Python Parameters | An array of Python Parameters to be used on the Databricks Job | String | In | ||
| pythonNamedParameters | Python Named Parameters | An array key=value pairs of Python Named Parameters to be used on the Databricks Job | String | In | ||
| sqlParameters | SQL Parameters | An array key=value pairs of SQL Parameters to be used on the Databricks Job | String | In | ||
| dbtParameters | DBT Parameters | An array of DBT Parameters to be used on the Databricks Job | String | In | ||
| pipelineFullRefresh | Pipeline Full Refresh | Should a full refresh be performed on the Databricks Pipeline Job | String | In | Y=Yes, N=No | |
| runId | Databricks Run Id | The Run Id of the executed Job on the Databricks side | String | Out |
Redwood_Databricks_RunJob_Template
AThis template definition is provided to facilitate creating definitions that run specificDatabricksjobs. It's functionality and parameters are the same as theRedwood_Databricks_RunJobdefinition. To create a definition, Choose New (from template) from the context-menu of Redwood_Databricks_RunJob_Template.
note
To provide a default value for the Connection in the Connection parameter of the template, you must use the full Business Key of the Connection: EXTConnection:<Partition>.<ConnectionName>. Example: EXTConnection:GLOBAL.MyDatabricksConnection
Parameters
| Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|
| connection | Connection | The Connection object that defines the connection to the Databricks application. | String | In | ||
| jobId | Job Id to run | This is the Job Id in Databricks to execute | String | In | ||
| sparkJarParameters | Spark Jar Parameters | An array of Spark Jar Parameters to be used on the Databricks Job | String | In | ||
| sparkSubmitParameters | Spark Submit Parameters | An array of Spark Submit Parameters to be used on the Databricks Job | String | In | ||
| notebookParameters | Notebook Parameters | An array key=value pairs of Notebook Parameters to be used on the Databricks Job | String | In | ||
| pythonParameters | Python Parameters | An array of Python Parameters to be used on the Databricks Job | String | In | ||
| pythonNamedParameters | Python Named Parameters | An array key=value pairs of Python Named Parameters to be used on the Databricks Job | String | In | ||
| sqlParameters | SQL Parameters | An array key=value pairs of SQL Parameters to be used on the Databricks Job | String | In | ||
| dbtParameters | DBT Parameters | An array of DBT Parameters to be used on the Databricks Job | String | In | ||
| pipelineFullRefresh | Pipeline Full Refresh | Should a full refresh be performed on the Databricks Pipeline Job | String | In | Y=Yes, N=No | |
| runId | Databricks Run Id | The Run Id of the executed Job on the Databricks side | String | Out |
Redwood_Databricks_ShowJobs
List all existing jobs in Databricks. Fetches information about the available Databricks Jobs. Job properties for returned jobs are written to the stdout.log file, the file named listing.rtx, as well as the Out parameter Job Listing.
Parameters
| Name | Description | Documentation | Data Type | Direction | Default Expression | Values |
|---|---|---|---|---|---|---|
| connection | Connection | The Connection object that defines the connection to the Databricks application. | String | In | ||
| filter | Job Name Filter | This filter can be used to limit the amount of jobs returned to those which name matches the filter. Wildcards * and ? are allowed. | String | In | ||
| listing | Job listing | The listing of all jobs available that match the input filter (or any if no input filter was provided) | Table | Out |
Procedure
Create a Connection To Databricks
- Navigate to Custom > Connections and choose
 .
.
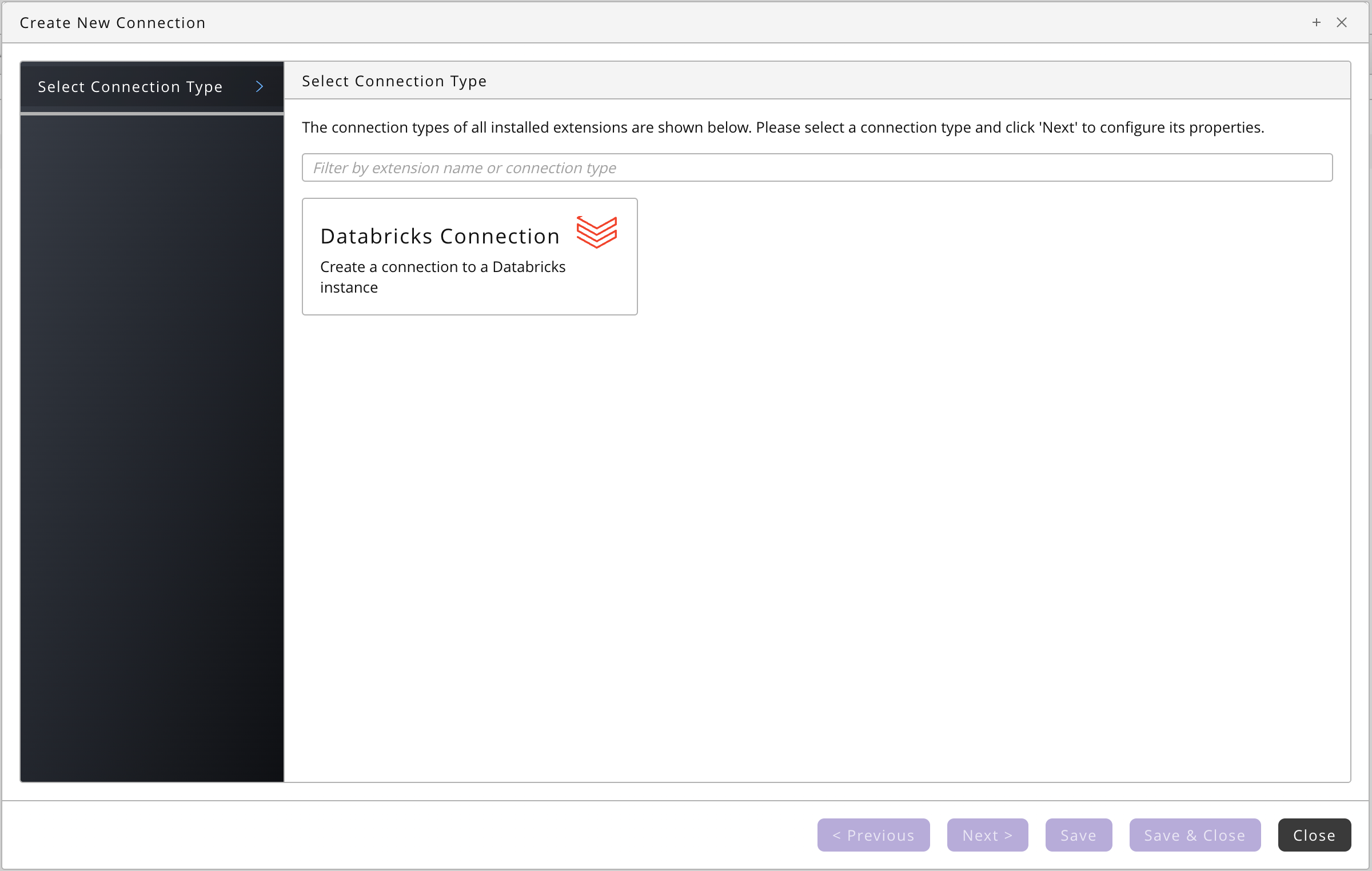
- Choose Databricks Connection under Select a Connection Type.
- Choose Next or Basic Properties, this is a screen for all components, you create a queue and process server for your Databricks connection, all required settings will be set automatically.
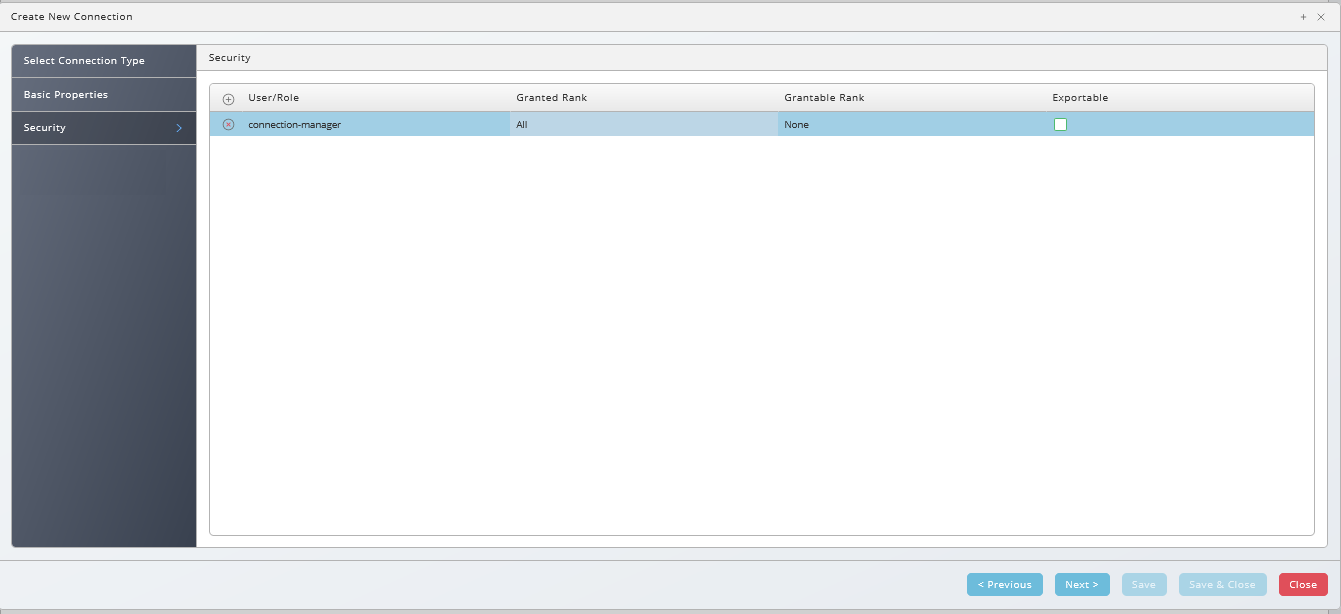
- Choose Next or Security, this is a screen for all components, choose to specify which roles can access the connection information.
- Choose Next Datbricks Connection Properties, this is specific for Infmatica-based components, for Databricks, you choose between Basic and Personal Access Token authentication:
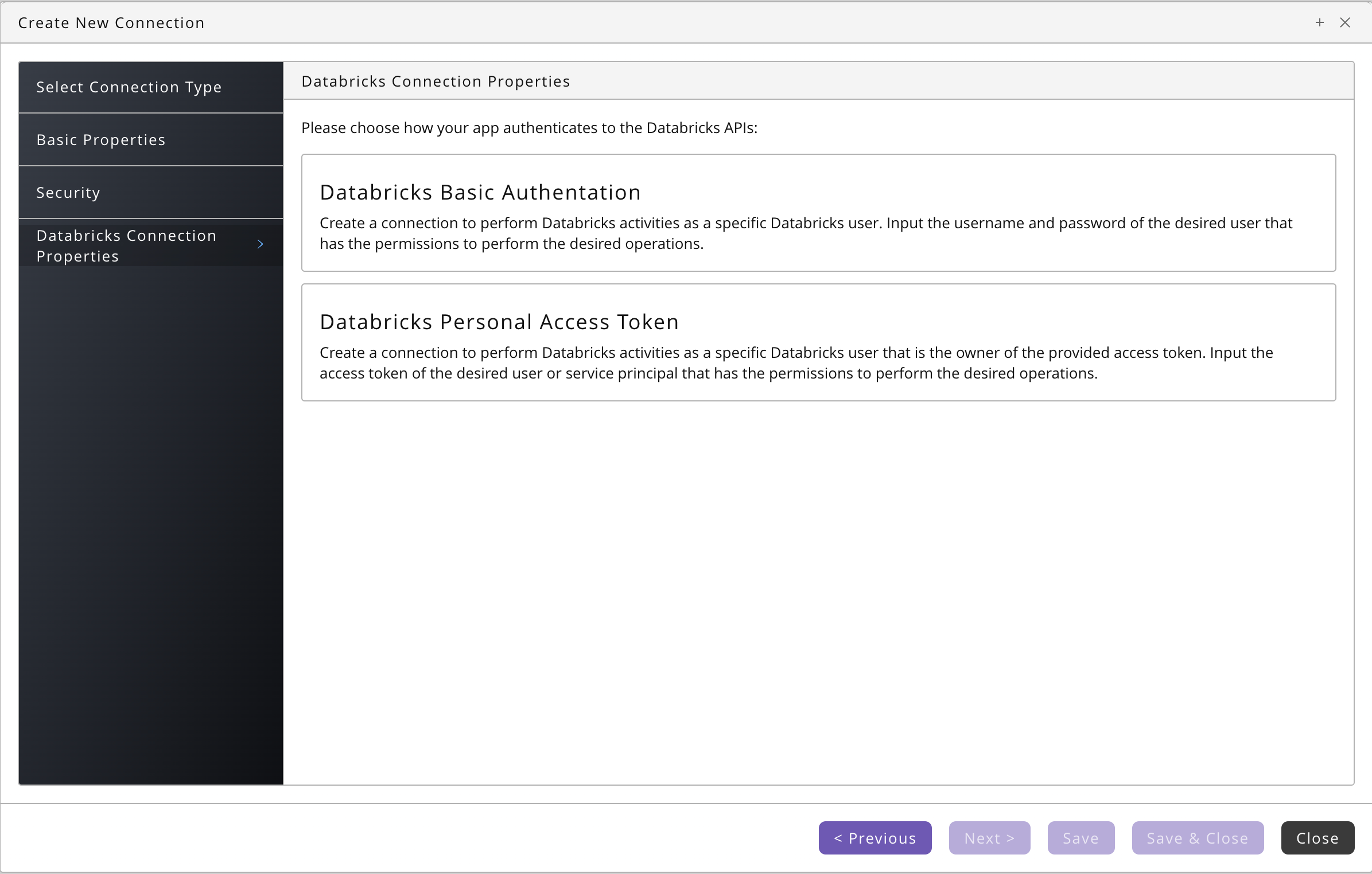
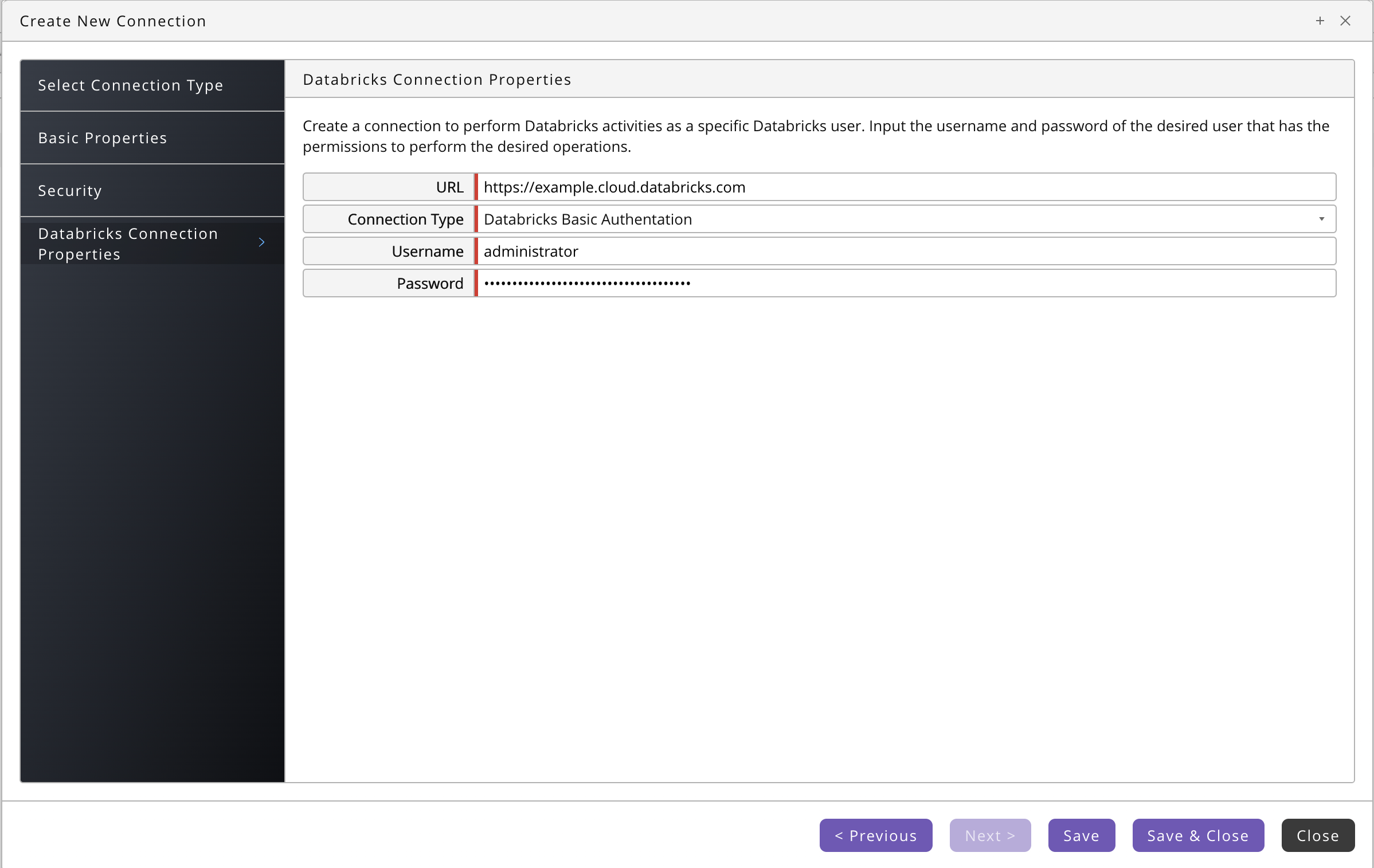
- For Basic authentication, you specify URL, Username, and your Password.
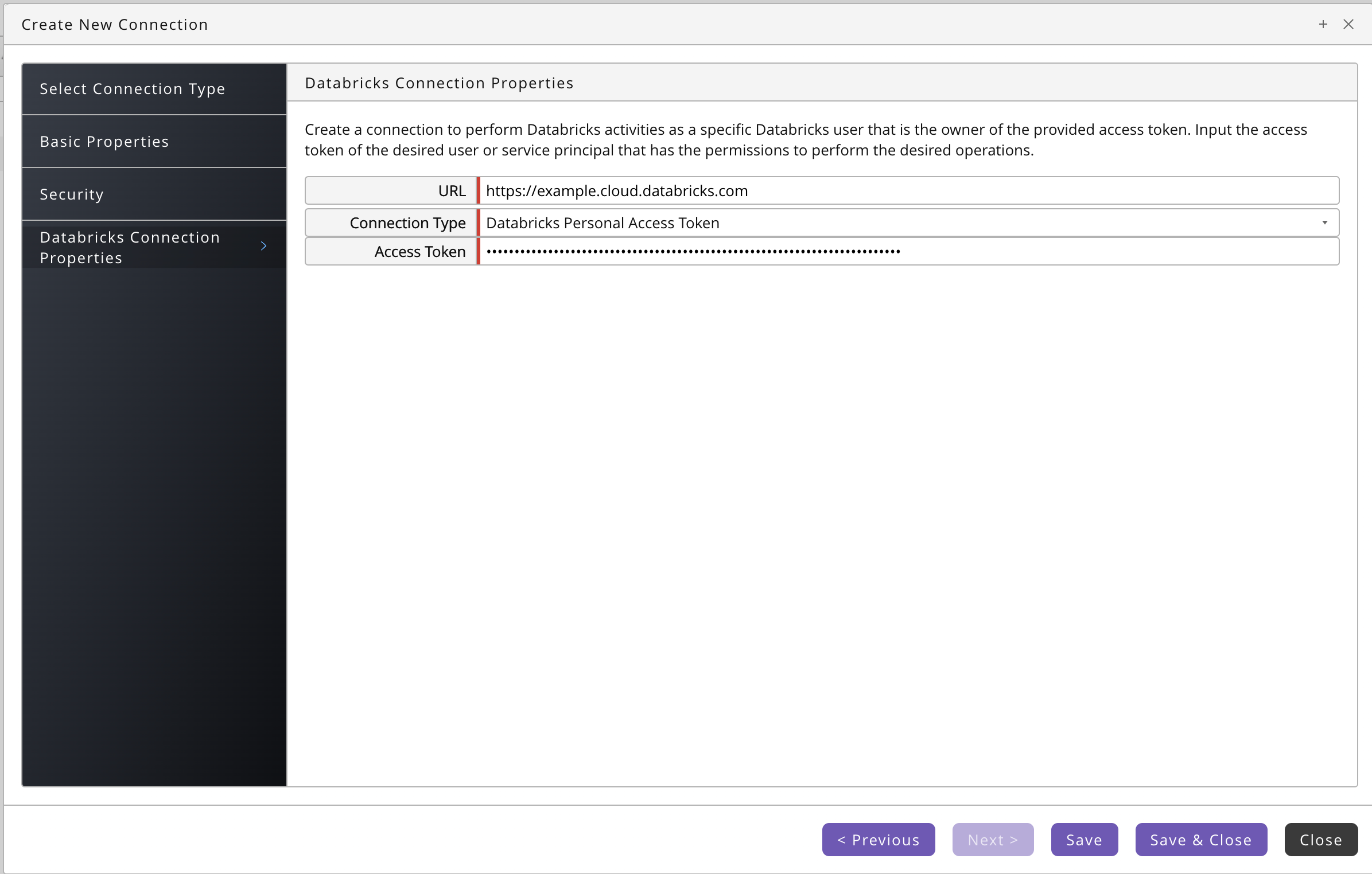
- For API Key authentication, you specify URL, Username, and your Access Token.
- For Basic authentication, you specify URL, Username, and your Password.
- Navigate to Environment > Process Server, locate your Databricks process server and start it, ensure it reaches status Running.
Listing Databricks Jobs
- Navigate to Definitions > Processes.
- Choose Submit from the context-menu of Redwood_Databricks_ShowJobs.
- Select the connection in the Connection field, specify an optional name filter in the Job Name Filter parameter, and choose Submit to list all available jobs.
Locating Connection Settings
- Navigate to Custom > Connections.
- The first line is used for filtering connections; you filter on Connection Type, Name, or Description by simply starting to type.